이전 글 : OpenCV image를 grid-based tiles로 변환하기 https://minseob.tistory.com/12
고등학생들이 공부하고 연구한 내용을 개인적으로 블로그에 정리한 글이다.
전문적이지 않으며 틀린 내용이 있을 수 있음을 미리 밝힌다.
강화학습이란 특정 환경에서 정의된 에이전트가 순차적 의사결정 문제에서 부여되는 누적 보상을 최대화하기 위해 시행착오를 통해 행동을 교정하여 학습하는 머신러닝의 한 분야입니다. 따라서 강화학습의 목적은 에이전트가 누적 보상이 최대화되는 행동을 선택하는 것입니다.
MDP란 아래 그림과 같은 그래프를 의미하고 상태, 행동, 전이 확률, 보상 함수, 감가율을 매개변수로 가집니다. MDP는 순차적 의사결정 문제의 하나로서 마르코프 성질을 가집니다. MDP에서 상태는 에이전트의 위치를 말합니다. 여기서는 1, 2, 3, 4가 상태가 될 수 있습니다. 행동은 에이전트의 움직임을 말합니다. 즉, 하나의 노드에서 다른 노드로 이동하는 것으로 여기서는 총 8가지가 있습니다.
$S$(상태) $=$ {1, 2, 3, 4}
$A($행동$) = ${1→2, 1→3, 2→1, 2→3, 2→4, 3→1, 3→2, 4→2}
$R($보상 함수) ← {-1, 0, 0.5, 10}
ex) R(s, a) = R(1, 1→2) : 0.5

감가율은 시간에 따른 보상의 가치를 나타내기 위해 미래의 보상에 곱하는 요소입니다. 감가율의 필요성은 무한합을 방지할 수 있습니다. 밑의 식을 살펴보면 반환 값이 감가율에 대한 등비급수의 형태를 가지는데 감가율이 없다면 이 급수는 발산하게 되어 계산이 무의미해집니다. 또 감가율은 미래의 가치를 낮게 평가함으로써 미래의 불투명도를 상징합니다.

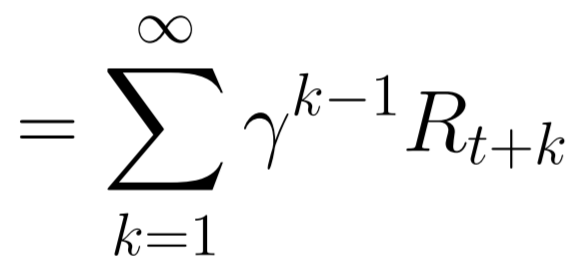

정책은 어떤 상태에서의 행동을 결정하는 함수로 어떤 상태에서 특정 행동을 할 확률을 의미합니다. 강화학습의 목적은 행동의 확률을 조정하여 학습하는 것이므로 누적 보상이 가장 높은 정책을 찾는 것이 이 연구의 주목적입니다.


가치함수는 MDP를 평가하기 위한 수단으로 상태 가치 함수와 행동 가치 함수로 나뉩니다. 이 중 상태 가치 함수는 어떤 상태에서의 가치를 평가합니다.



행동 가치 함수는 큐 함수라고도 불리는데 이는 상태와 행동의 가치를 모두 평가합니다.

가치 함수를 구하기 위해서는 벨만 방정식을 사용합니다. 벨만 방정식은 재귀를 이용하여 가치함수를 구하는 방정식으로 벨만 기대 방정식과 벨만 최적 방정식으로 이루어져 있습니다.

벨만 방정식을 유도하기 위해서는 처음으로 가치함수를 반환 값으로 표현하는 식을 변형시킵니다. 이후 가치 함수의 정의에서 기댓값 식을 풀어서 다음과 같이 가치 함수를 큐함수로 구하고 큐함수를 가치함수를 통해 구할 수 있도록 변형합니다.

방금 전의 식에 처음의 식을 대입하여 식을 재귀적으로 유도할 수 있습니다. 그리고 이 식을 벨만 기대 방정식이라고 합니다.
그리고 앞서 살펴보았던 벨만방정식의 가치함수를 최적 가치함수로 바꾸면 벨만 최적 방정식을 구할 수 있습니다.

큐러닝이란 강화 학습의 기법 중 하나로, 행동하는 정책과 학습하는 정책을 분리시켜 모델을 학습시키는 방법입니다.
큐러닝은 epsilon-greedy 알고리즘을 사용해 상태로부터 행동을 선택합니다.
epsilon-greedy 알고리즘이란, 입실론의 확률로 탐험을 하고, 아니면 탐색을 합니다.


또, 큐러닝은 벨만 최적 방정식을 이용해 Q값을 업데이트합니다.
DRL은 심층 강화 학습의 줄임말로, 강화학습에 딥러닝을 적용한 것입니다.
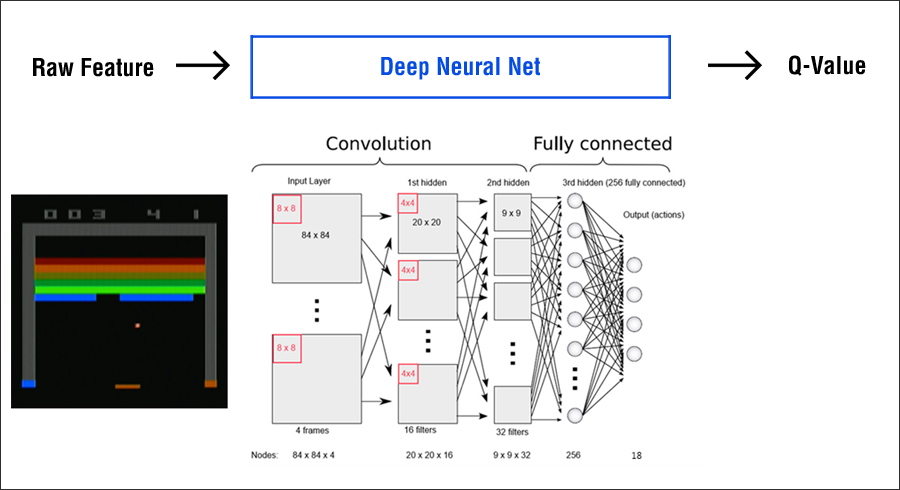
DQN은 심층 강화학습의 일종으로, 오프폴리시, 리플레이 메모리와 미니배치, 타겟신경망을 사용한다는 것이 특징입니다.
Rainbow DQN이란 DQN에서 파생된 7가지 기법들이 혼합된 기법입니다.
아래 그래프에서 보시다시피 Rainbow DQN은 다른 각각의 기법들의 성능을 능가합니다.
Rainbow DQN에 혼합된 기법들은 DQN, Double DQN, Prioritized Experience Replay, Dueling Networks, Multi-step learning, Distributional RL, Noisy Networks입니다.

DQN은 기본적인 DQN입니다.
Double DQN은 두 개의 Q값, 즉 main Q, target Q 두 개를 두고 서로 보정하면서 학습합니다.
Prioritized Experience Replay는 중요하고 희소한 경험에 가중치를 주는 기법입니다.
Dueling DQN은 Network Q 값을 V와 A 두 개로 나누어 서로 결투시키는 방식으로 학습하게 하는 기법입니다.
Multi-step learning은 보시는 사진과 같이 한 번에 여러 개의 스텝을 진행하고 업데이트하게 하는 기법입니다.
Distributional RL은 가치를 하나의 스칼라 값이 아닌 이산 확률 분포의 기댓값으로 예측하게 하는 기법입니다.
Noisy Networks는 신경망의 가중치에 가우시안 노이즈를 적용해 탐험하게 하는 기법입니다.
이 내용을 바탕으로 Rainbow-DQN을 적용해보았습니다.
하지만 학습이 원활히 이루어지지 않아서 결국 성공적인 에이전트 개발에는 실패하였습니다.
이렇게 하여 1년간의 정보알앤이 연구가 끝나게 되었다.
비록 성공적인 결과를 내지는 못했지만 정말 좋은 경험이었다고 생각한다.
<2021 정보 R&E>
2021 정보 R&E 주제 소개 https://minseob.tistory.com/6
2021 정보 R&E 주제 소개
R&E 는 Research & Education의 약자로 1년에 걸쳐서 하는 탐구 프로젝트를 말한다. 현재 재학 중인 전북과학고등학교에서는 정보, 수학, 물리, 화학, 생물, 지학 중 한 과목에 대하여 모든 1학년 학생이
minseob.tistory.com
OpenCV-python를 이용하여 Unrailed! 윈도우 창 캡쳐하기 https://minseob.tistory.com/7
OpenCV-python를 이용하여 Unrailed! 윈도우 창 캡쳐하기
이전 글 : 2021 정보 R&E 주제 소개 https://minseob.tistory.com/6 게임을 플레이하는 ai를 만들려면 가장 먼저 게임 화면을 실시간으로 캡처해서 ai가 인식할 수 있도록 해야 한다. 이를 수행해주는 것이 바
minseob.tistory.com
OpenCV image를 grid-based tiles로 변환하기 https://minseob.tistory.com/12
OpenCV image를 grid-based tiles로 변환하기
이전 글 : OpenCV-python를 이용하여 Unrailed! 윈도우 창 캡쳐하기 https://minseob.tistory.com/7 OpenCV를 이용하여 게임 화면을 캡쳐한 다음에는 이 화면을 에이전트가 맵을 파악할 수 있도록 grid-based til..
minseob.tistory.com
Rainbow DQN 강화학습 알고리즘 적용하기 https://minseob.tistory.com/21
Rainbow DQN 강화학습 알고리즘 적용하기
이전 글 : OpenCV image를 grid-based tiles로 변환하기 https://minseob.tistory.com/12 고등학생들이 공부하고 연구한 내용을 개인적으로 블로그에 정리한 글이다. 전문적이지 않으며 틀린 내용이 있을 수..
minseob.tistory.com
'정보 > R&E' 카테고리의 다른 글
| OpenCV image를 grid-based tiles로 변환하기 (0) | 2021.08.30 |
|---|---|
| OpenCV-python를 이용하여 Unrailed! 윈도우 창 캡쳐하기 (0) | 2021.07.14 |
| 2021 정보 R&E 주제 소개 (0) | 2021.07.13 |