이 글은 POSTECH AI CAMP에 참여하여 연구원님께 수업받으며 간단하게 내용을 정리한 것이다.
틀린 내용이 있을 수 있으며, 수학적으로 엄밀하지 않을 수 있음을 미리 밝힌다.
| 선형대수학 이란? 선형 : 직선(일차의) 대수학 : 방정식을 공부하는 학문 -> 연립 일차 방정식 |
| 차원 차원 : 어느 지점을 설명하는데 필요한 정보의 숫자<->벡터를 설명하기 위해 필요한 원소의 개수 기저(basis) : 벡터를 표현 하기 위한 기본단위 ex) 2차원에서 벡터를 표현하려면 두 개의 기저가 필요함 |
| 벡터 공간 벡터 공간 : 덧셈과 스칼라곱 연산으로 이루어진 집합. 이때 이 원소들을 벡터라고 정의함 |
| 벡터의 덧셈 $X=[a_1 , a_2] , Y=[b_1,b_2]$ $X+Y=[a_1+b_1,a_2+b_2]$ |
| 벡터의 크기(norm)와 거리(distance) $X=[a_1,a_2, ... , a_n]$ 일때 $X$의 크기는 ||$X$||로 표기한다. $||X||$=$\sqrt{a_{1}^{2} +a_{2}^{2} +...+a_{n}^{2}}$ $X=[a_1,a_2, ... , a_n] , Y=[b_1,b_2, ... , b_n]$일때 두 벡터 사이 거리는 $d(x,y)$로 표기한다. $d(x,y)=||x-y||=\sqrt{(a_1-b_1)^2+(a_2-b_2)^2+...+(a_n-b_n)^2}$ |
| 벡터의 내적 $X=[a_1 , a_2] , Y=[b_1,b_2]$ $X\cdot Y=a_1b_1+a_2b_2+...+a_nb_n$ *$X\cdot Y=||X||||Y||cos\theta$로 정의하면 각을 알고있어야하는 문제가 생긴다. |
| 코사인 유사도 내적의 개념으로 두 데이터 사이의 유사도를 정의할 수 있다. 내적을 이용하여 두 데이터 사이의 코사인 값을 계산한후, 유사할수록 코사인값이 1에 가깝고 유사하지 않을 수록 0에 가까운 것을 이용하여 닯은 데이터와 그렇지 않은 데이터를 분류할 수 있다.  |
| 행렬 $A=\begin{bmatrix} a_{11} & a_{12} & ... & a_{1n}\\ a_{21} & a_{22} & ... & a_{2n}\\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & ... & a_{mn} \end{bmatrix}$을 $(m \times n)$-행렬이라고 부른다. $A=(a_{ij})_{m \times n}=(a_{ij})$로 표기하기도 한다. 행 : $A$의 $i$-번째 가로줄 <-> $[A]_i$ 열 : $A$의 $j$-번째 세로줄 <-> $[A]^j$ 또한 모든 벡터는 열벡터로 생각하기로 한다. |
| 행렬의 덧셈과 곱셈 크기가 같은 두 행렬 $A=(a_{ij})$와$B=(b_{ij})$에 대하여, 두 행렬의 합 $A+B$는 $(i,j)$-성분이 $a_{ij}+b_{ij}$인 행렬이다. $(m \times n)$-행렬 $A = (a_{ij} )$와 $(n \times l) B = (b_{jk} )$에 대하여, 행렬곱 $AB$는 $ (m \times l)$-행렬로서, $(i,k)$-성분이 $A$의 $i$번째 행 $[A]_i$와 $B$의 $k$번째 열 $[B]^k$의 내적 $[A]_i \cdot [B]^k=a_{i1}b_{1k}+a_{i2}b_{2k}+...+a_{in}b_{nk}$으로 정의한다. |
| 행렬은 인간의 언어를 컴퓨터가 이해하는 숫자로 바꾸는 '함수'다 예를 들어 '평면위의 벡터를 x축에 대해 대칭시킨다' 라는 언어가 있다고 하자. 행렬 $A=\begin{bmatrix} 1 & 0\\ 0 & -1 \end{bmatrix}$에 2차원 벡터(열벡터)를 곱하면 대칭시킨 점이 된다. 평면위의 백터 $x=\begin{bmatrix} 1\\ 2 \end{bmatrix}$로 예를 들어보자. $Ax=\begin{bmatrix} 1 & 0\\ 0 & -1 \end{bmatrix}\begin{bmatrix} 1\\ 2 \end{bmatrix} =\begin{bmatrix} 1\\ -2 \end{bmatrix}$가 되어 결과물 $Ax$가 벡터 $x$를 $x$축 대칭시킨 값이 됐다. 행렬이 함수라는 것을 생각한다면 $Ax$에서 $A$가 $x$보다 먼저 나오는 것이 자연스럽게 이해된다. $f(x)$에서 $f$가 먼저 나오는 것처럼 말이다. |
| 행렬의 고윳값, 고유벡터 행렬마다 어떤 고유한 벡터가 있어서, 그 벡터를 곱했더니 그 벡터의 상수배가 나오는 경우가 있다. 이때, 그 상수를 고윳값, 그 벡터를 고유벡터라고 한다. |
| 전치 행렬 행과 열을 뒤집은 행렬이다. |
| 대칭 행렬 전치를 해도 자기 자신이 나오는 행렬이다. |
| 대각 행렬 대칭 행렬 중 대각성분만 값이 존재하고 나머지는 0인 행렬이다. 거듭제곱하기 쉽다는 특성이 있다. |
| 항등 행렬(I) 대각 행렬 중 대각성분이 모두 1인 행렬. 행렬의 곱셈의 항등원이다. $AI=IA=A$ |
| 직교 행렬 $A^TA=AA^T=I$를 만족시키는 행렬이다. 곱셈의 대한 항등원으로 자신의 전치행렬을 가지는 행렬이다. |
| 고윳값분해(정사각행렬에 대해서만 사용가능) $A=P^TDP$ P:직교행렬(열벡터의 각각의 고유벡터), D:대각행렬(대각성분이 고윳값이다.) 이를 이용해서 행렬의 거듭제곱을 손쉽게 할 수 있다. $A^{100}=(P^TDP)^{100}=(P^TDP)(P^TDP)(P^TDP)...=P^TD^{100}P$  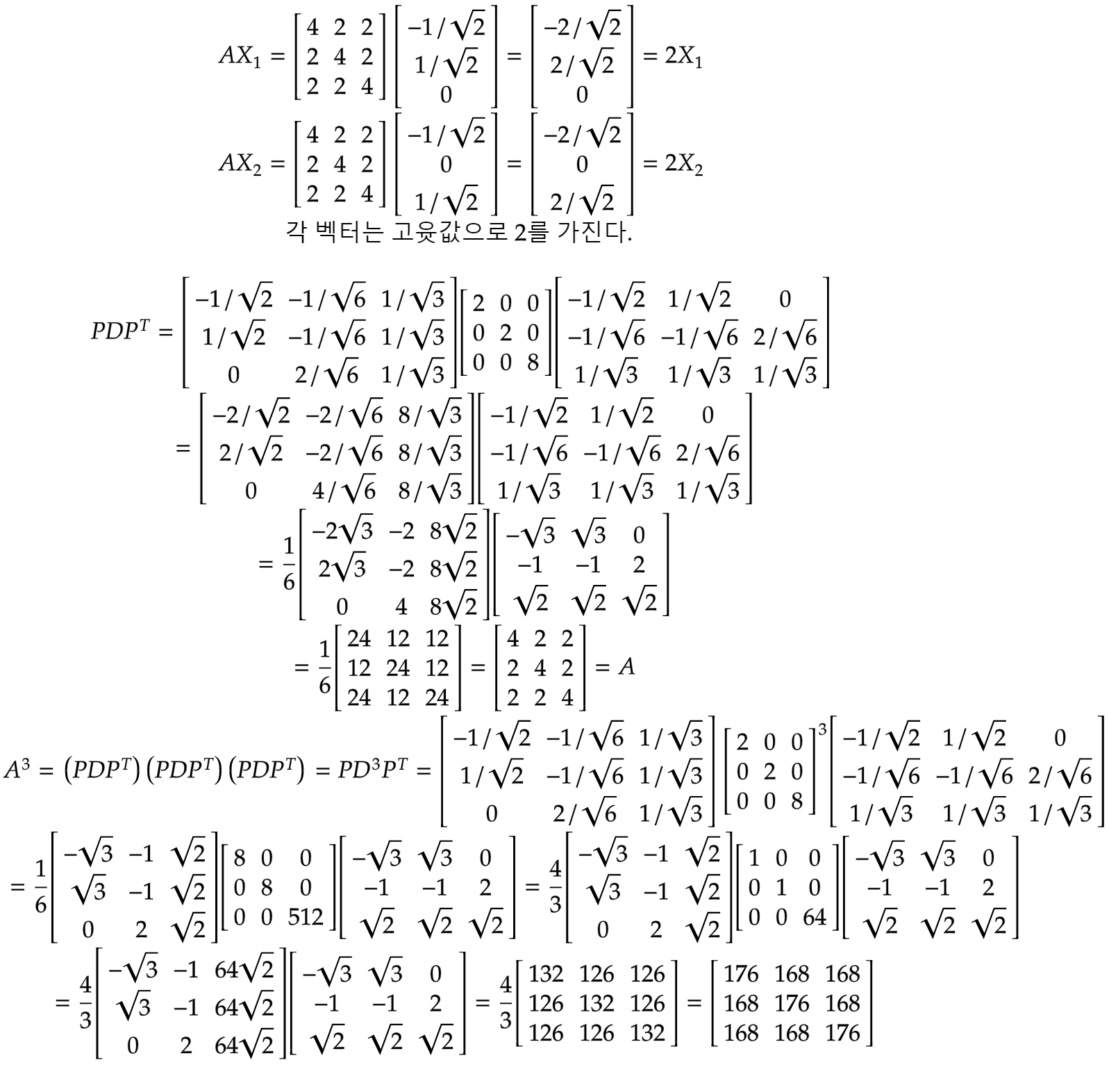 |
| 특잇값 분해(SVD) $X$가 직사각행렬이라 하자. $X-(m\times n), X^T=(n\times m) $일때 $X^TX-(n\times n)$은 고윳값 분해가 가능하다. 이 고윳값이 $𝜎_{1}, 𝜎_{2}, ...$일때 각각에 루트를 씌운것이 X의 특징적인 값(특잇값)이 된다.($X^TX$에 $X$의 성분이 두번 반영되었기 때문) $X=U^T𝛴V$ |
| 주성분분석(PCA) 행렬에 고윳값이 있듯이, 이미지와 같은 데이터도 행렬로 표현되니 주성분을 찾아낼 수 있을 것이다. 그래서 PCA는 데이터에 가장 가까운(분산이 잘 보존되는) 초평면을 정의한다음, 이 초평면에 데이터를 사영시키는 방법이다. 이를 수학적 이론으로 표현해보자. 데이터를 $X$라는 행렬로 나타냈다고 하자. 분산행렬 $S=1/n *X^TX$인데 이때 이 꼴이 특잇값분해에서 나온 것과 같다. 따라서 특잇값을 구하고 고유벡터를 구하는 과정이 분산을 보존하는 것과 같은 의미를 가지게 되는 것이다. |
'수학 > 선형대수학' 카테고리의 다른 글
| 프리드버그 선형대수학 1.1 개론 (0) | 2021.07.08 |
|---|---|
| 선형대수학 공부계획 (0) | 2021.06.29 |